Visualizzare la conoscenza con Wikidata

Le pagine di Wikipedia più viste nell’ultimo mese
18 Settembre 2023
Come aggiungere un elemento su Wikidata
21 Settembre 2023
La prima volta che mi hanno mostrato Wikidata, nel 2016, ho pensato che fosse la cosa più incredibile successa nell’ultimo decennio sul web. Passai un giorno solo ad immaginare le possibilità che si aprivano. Non era rivoluzionaria la tecnologia, o le informazioni contenute. Era rivoluzionaria la dimensione, il fatto che sia tutto liberamente accessibile, ed in generale la sua ambizione.
Wikidata nasce con un obiettivo molto particolare: rappresentare il sapere umano in un formato che sia accessibile sia dagli esseri umani che dai computer. A differenza di Wikipedia, in cui abbiamo una voce composta da testo e immagini, in Wikidata abbiamo elementi. Ogni elemento è definito da un codice univoco, una Q seguito da un numero. Q1 rappresenta l’universo. Q2 la terra, Q3 la vita, Q5 l’essere umano, Q36153 Beyoncé, e via dicendo.
Quello che è davvero interessante è come questi elementi vengono descritti.In un dataset tabulare normalmente abbiamo una riga per ogni elemento e sulle colonne le sue proprietà. In Wikidata invece le proprietà vengono descritte attraverso connessioni con altri elementi. Riprendendo l’esempio precedente, Beyoncé (Q36153) è un essere umano (Q5), risiede a Bel Air (Q86768), ed è nata ad Houston (Q16555). In quanto connessioni, possono essere lette in entrambe le direzioni: se cerco i residenti a Bel Air, posso trovare Beyoncé.
Come vengono esplicitati queste connessioni? Attraverso altri tipi di elementi, chiamati proprietà, definite da una lettera, P, ed un numero. Ad esempio, la proprietà “coniuge” (P26) lega Beyoncé a Jay-Z (Q62766).
Cosa possiamo visualizzare con Wikidata
Ora, vi chiederete, ma è davvero necessario tutta questa struttura per avere delle informazioni facilmente ottenibili con un breve testo? Forse non per sapere chi è il partner di Beyoncé. Ma immaginate di aumentare il numero di entità a decine, centinaia di milioni, connessi da più di 11.000 tipi di proprietà. E di poter navigare questa immensa ragnatela in ogni direzione utilizzando tutte le possibili combinazioni. Le proprietà possono essere infatti utilizzate sia per circoscrivere la ricerca, sia per espanderla. Abbiamo così la possibilità di avere la lista di tutti gli esseri umani presenti su wikidata, e per ognuno sapere il colore degli occhi.

Tendenzialmente, marroni.
Oppure possiamo visualizzare tutti gli ospedali in un’area geografica, l’anno di costruzione, la capienza, sapere quali reparti includono. O quanti gruppi musicali sono presenti su wikidata, raggrupparli per anno di fondazione, e poi dividerli per genere musicale, come visibile in questo grafico.
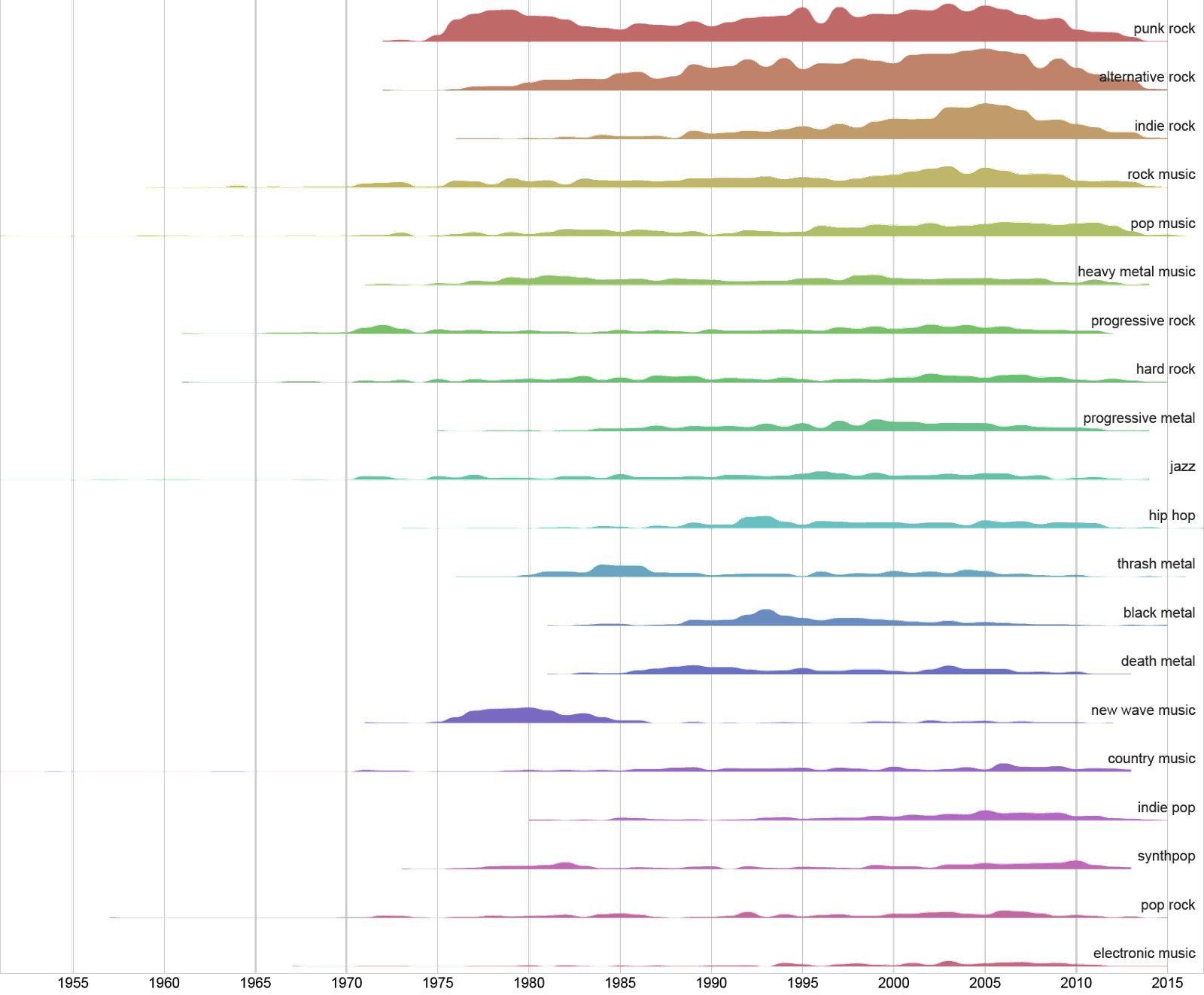
Tutti i gruppi musicali presenti su Wikidata, raggruppati per anno di fondazione e per genere principale (fonte: A visual exploration of musical bands on Wikidata).
Per chi lavora con i dati, Wikidata è utilissimo per le operazioni di espansione dei dati, o per disambiguare casi di omonimia. Recentemente, per realizzare una visualizzazione degli autori più citati da Calvino, Wikidata si è rivelato un efficace alleato. La visualizzazione è parte della tesi di Martina Melillo “L’Arcipelago dei Nomi, information design collaborativo per le digital humanities” ed ha l’obiettivo di progettare un’interfaccia visiva utile ad indagare chi è stato citato da Italo Calvino nei suoi saggi. Per ogni persona citata sono stati raccolti con Wikidata numerose informazioni aggiuntive, tra cui periodo storico, occupazioni principali e secondarie. L’interfaccia offre una diversa visualizzazione per ognuna di queste informazioni. Nello screenshot di seguito, ad esempio, è possibile vedere in che punto del saggio vengono citate le persone e qual è il periodo storico in cui sono vissute, così da indagare se esistono pattern nell’evoluzione delle opere di Italo Calvino
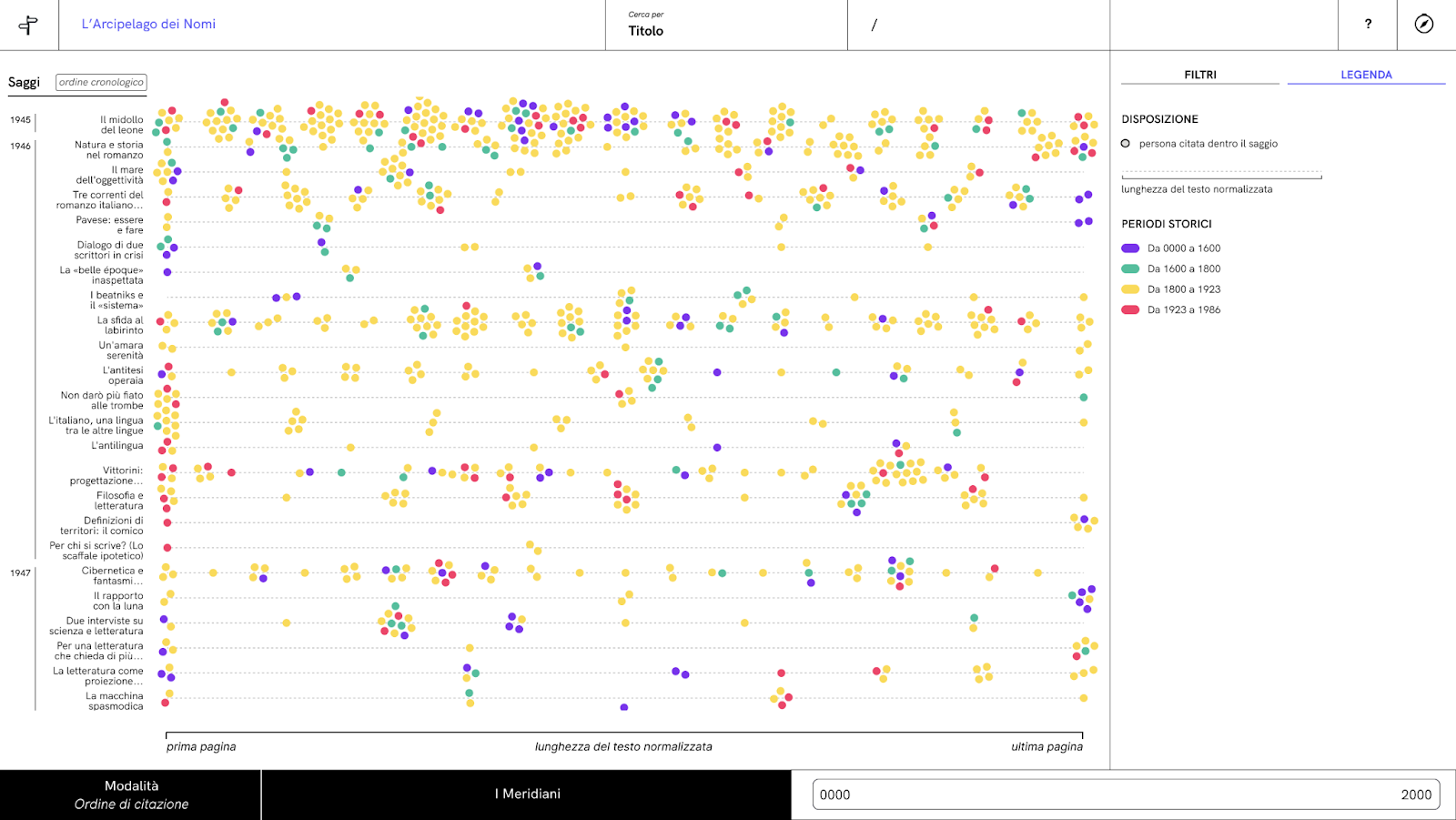
Schermata del progetto di tesi sviluppato da Martina Melillo, “L’Arcipelago dei Nomi, information design collaborativo per le digital humanities”. CC BY-SA 4.0 Martina Melillo
Usare Wikidata come fonte di informazioni per arricchire i nostri dataset è più semplice di quanto si possa immaginare. Sempre più software permettono di raccogliere informazioni tramite interfacce visive, tra questi val la pena di citare il servizio di riconciliazione fornito da OpenRefine, che rende facilmente automatizzabile la ricerca di nomi presenti in una colonna di un foglio di calcolo in Wikidata, e creare un collegamento. Una volta creato il collegamento, Wikidata ci dà la possibilità di estendere i nostri dati chiedendo informazioni collegate, in questo caso data e luogo di nascita.
Alcuni problemi legati a Wikidata
L’uso di Wikidata all’interno di progetti scientifici pone però anche una serie di criticità. La prima, e più ovvia, è che Wikidata non rappresenta (ancora) tutta la conoscenza. Riprendendo gli esempi precedenti, non tutti i gruppi musicali sono su Wikidata, né gli ospedali. Spesso Wikidata, come nel caso degli altri progetti Wikimedia, offre il punto di vista dei paesi più ricchi e sviluppati, lasciando altre culture ed aree geografiche sottorappresentate.

Come per gli articoli Wikipedia, anche su Wikidata la maggior parte delle informazioni riguarda un punto di vista geografico e culturale molto specifico. Immagine di Ralph Straumann e Mark Graham.
Per ovviare a questo problema Wikimedia Foundation ha avviato numerosi progetti per aumentare la copertura e la diversità anche su Wikidata. Resta comunque importante tenerlo in mente se si vuole usare Wikidata per elaborare visioni globali di un fenomeno: il risultato molto spesso ci racconta più di Wikidata e dei suoi volontari che del fenomeno in sé.
Una seconda criticità è la volatilità delle informazioni: Wikidata è in continua e rapida evoluzione. Tendenzialmente le informazioni aumentano, ma possono anche cambiare. Un’attenzione che abbiamo sviluppato nel nostro laboratorio quando usiamo dati da questa fonte, è quella di tenere traccia della data di raccolta dei dati, cercando di raccoglierli tutti ad un dato momento e a scaglioni.
Una terza criticità è l’autorialità delle informazioni: chi ne è responsabile? Essendo il progetto basato sui volontari, è un elemento che viene spesso evidenziato quando si usano i dati di questa piattaforma. In realtà, la maggior parte delle connessioni possono essere supportate da delle fonti. Questa è anche una pratica consigliata ai volontari. Sicuramente questo è l’aspetto su cui più deve crescere Wikidata in questo momento, e su cui si potrebbe puntare con progetti dedicati.
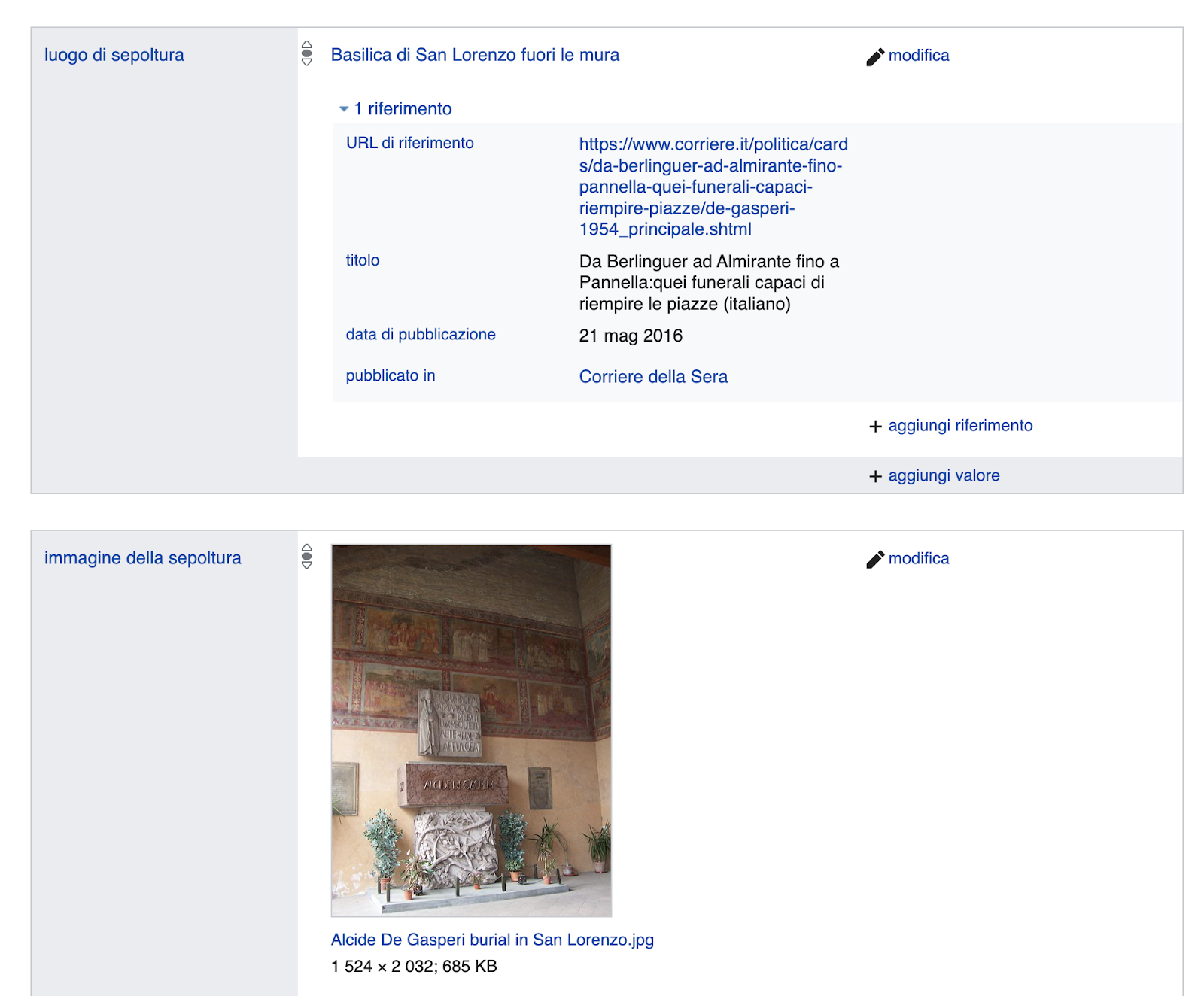
Esempio di utilizzo di fonti in Wikidata: il luogo di sepoltura di Alcide de Gasperi è supportato da un articolo del Corriere.
Infine, Wikidata pone una sfida da non sottovalutare: offrire un punto di vista inclusivo ma condiviso e centralizzato. Tematiche divisive, ad esempio eventi storici vissuti in maniera molto differente da due o più gruppi di persone, richiedono un grande sforzo di cooperazione. Se su Wikipedia c’è la possibilità di avere diverse varianti linguistiche dello stesso articolo, con punti di vista il più possibile neutrali ma differenti sullo stesso tema, su Wikidata tutti gli editori devono accordarsi su una prospettiva condivisa.
Partecipare alla crescita
Le criticità elencate non vanno a smorzare le potenzialità della piattaforma. Impongono sicuramente delle attenzioni nell’utilizzo dei dati, ma questo a ben pensare accade (o dovrebbe accadere) con qualsiasi fonte di dati.
Piuttosto, dovrebbero essere uno stimolo per tutti per capire quanto questo progetto sia troppo importante per non partecipare alla sua crescita, al suo sviluppo, ed alla correttezza delle informazioni inserite. Se volete cominciare, a questo link potete scoprire quanto è fonda la tana del bianconiglio.
Michele Mauri
Michele Mauri è ricercatore presso il Politecnico di milano e co-direttore del gruppo di ricerca DensityDesign. Il gruppo di ricerca indaga il rapporto tra dati e design della comunicazione, con particolare attenzione alla progettazione di visualizzazioni e infografiche. È co-autore della piattaforma di visualizzazione open-source RAWGraphs.
Iscriviti ad Arkivia
Questo articolo è il nuovo contributo della newsletter Arkivia, dedicata alla cultura libera e all’open access al patrimonio culturale. Iscriviti per seguire gli aggiornamenti su questi temi.
Immagine: Beyoncé – Tottenham Hotspur Stadium – 1st June 2023 (35 of 118), di Raph_PH, CC BY 2.0, da Wikimedia Commons



_(52946287085).jpg){kind=link}